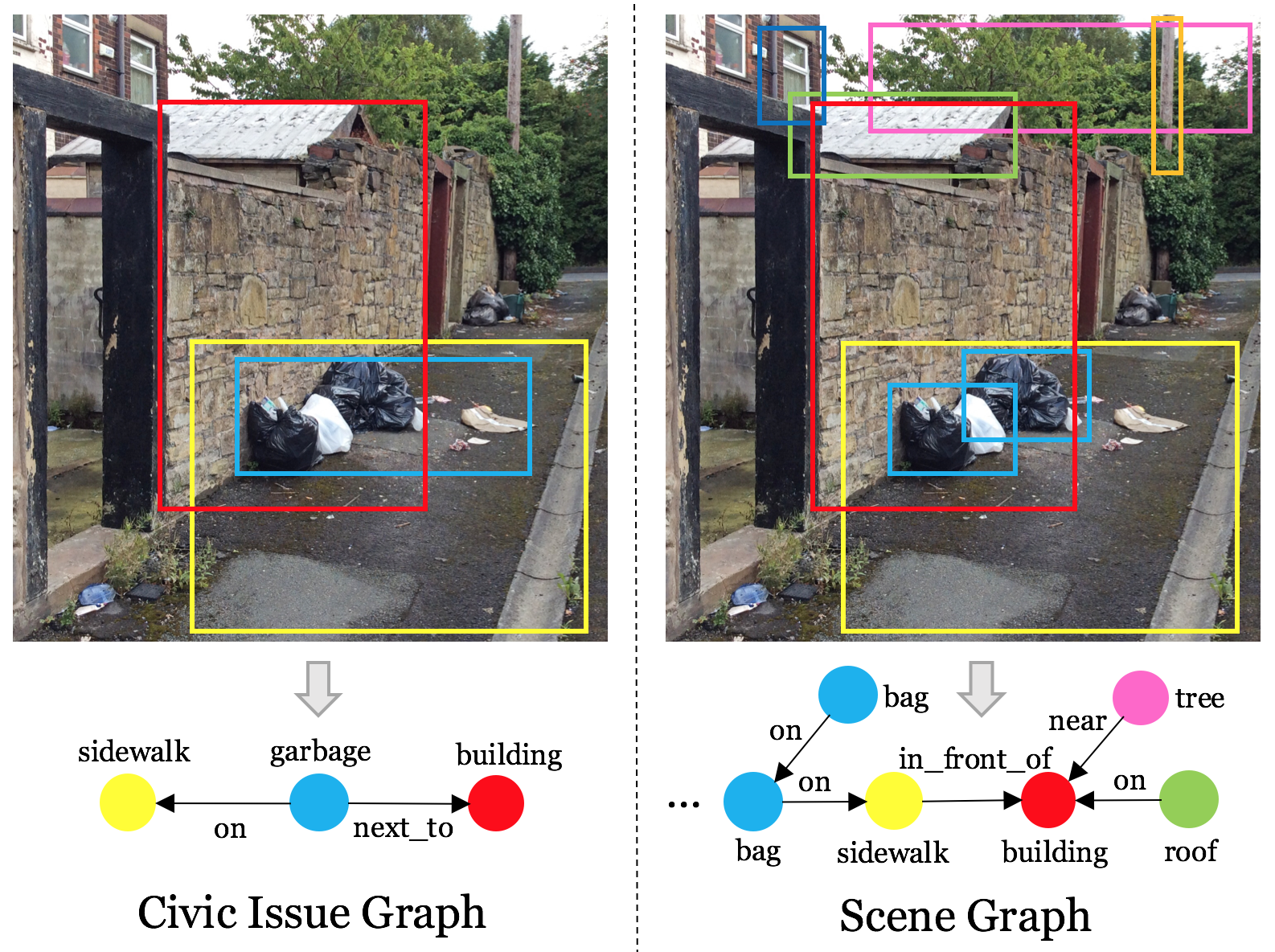
Improving Visual Alignment in Vision–Language Models
I am working on making VLMs align visual and textual representations more reliably and earlier in the network, so vision can actually influence reasoning instead of arriving late to the party.
Temporal Personalization (usable for Jarvis)
I am exploring temporal personalization: modeling preferences and context that change over time, so assistants can be helpful in a way that feels natural.